報告:えらぼーと結果の集計による世論調査
えらぼーと( https://vote.mainichi.jp/ )というのがあります。簡単な質問でどの政党に自分の思想が近いかわかるっぽいです。
このサイトはツイッターで結果を自分語りすることができて、
日本を、トリモロス! 考えが近い政党は維新(39%)でした。えらぼーと2019参院選を試してみよう! #えらぼーと #ボートマッチ #選挙 #参院選 https://t.co/c2vvJ9k0fJ @mainichieravote
というような形式でツイッターに投稿されます。これを検索すれば、ツイッターでの政党支持の傾向がわかるんじゃないかと思って、1700件ほど収集してみました。
概要
1738ツイートが取得でき、分析対象はそのうちリツイートを除く1304ツイートとします。さらに、その中で有効であったツイート(分析結果についてのツイート)は845個でした。

こんな感じで抽出できました。
from twitter import * from auth import auth import os, sys, json, re, time def search(q, ): t, _ = auth() allmsg = t.search.tweets(q=q, count=200)["statuses"] for i in range(30): max_id = allmsg[-1]['id'] - 1 msg = t.search.tweets(q=q, count=200, max_id=max_id)["statuses"] if len(msg) == 0: break allmsg += msg time.sleep(1) return allmsg def main(): js = search(q='#えらぼーと #ボートマッチ #選挙 #参院選 https://vote.mainichi.jp/ @mainichieravote') with open('result.json', 'w') as f: json.dump(js, f, ensure_ascii=False, indent=2) if __name__ == '__main__': main()
auth.pyの中身は
t = Twitter(
auth=OAuth(oauth_token, oauth_secret, CONSUMER_KEY, CONSUMER_SECRET)
)
t_media = Twitter(
auth=OAuth(oauth_token, oauth_secret, CONSUMER_KEY, CONSUMER_SECRET),
domain='upload.twitter.com'
)
return t, t_media
みたいになってます。これで生成されたresult.jsonに対して以下の処理をします。
from twitter import * from auth import auth import os, sys, json, re, time def main(): ans = [] t, _ = auth() with open('result.json', 'r') as f: js = json.load(f) for x in js: if not "retweeted_status" in x.keys(): xx = re.findall( r'考えが近い政党は(.*)でした。えらぼーと2019参院選を試してみよう! #えらぼーと #ボートマッチ #選挙 #参院選', x['text'] ) if xx != []: ans.append(xx) print(xx) print(len(js), len(ans)) if __name__ == '__main__': main()
pythonのcollections.Counterで結果を見てみます。
[('国民', 213),
('社民', 201),
('維新', 200),
('幸福', 179),
('立憲', 97),
('共産', 92),
('公明', 88),
('オリ', 87),
('自民', 26),
('労働', 19),
('ありません', 2),
('◯◯', 1),
('❌❌', 1),
('幸福実現党', 1),
('れ新', 1),
('安楽', 1),
('N国', 1),
('○○', 1),
('立憲民主党', 1)]
一部、ツイートを改変した人がいるために変なのがヒットしてます。 国民民主党、社民党、維新の会、幸福実現党、の順に支持されているようです…
支持の組み合わせ別では、
[('幸福', 156),
('維新', 150),
('国民', 134),
('公明', 60),
('社民', 50),
('共産、社民', 40),
('立憲', 23),
('社民、オリ', 18),
('オリ', 16),
('立憲、社民', 15),
('立憲、共産、社民', 14),
('立憲、国民', 14),
('国民、社民', 12),
('自民', 12),
('国民、維新', 11),
('維新、幸福', 10),
('公明、維新', 10),
('共産、社民、オリ', 9),
('国民、共産、社民', 8),
('立憲、社民、オリ', 6),
('立憲、共産、社民、オリ', 5),
('公明、国民', 4),
('労働', 4),
('自民、維新', 4),
('自民、公明', 4),
('国民、オリ', 4),
('立憲、国民、共産、維新、社民、オリ、労働', 3),
('立憲、国民、共産、社民', 3),
('国民、社民、オリ', 2),
('国民、共産、社民、オリ', 2),
('立憲、共産、社民、オリ、労働', 2),
('立憲、オリ', 2),
('立憲、国民、社民、オリ', 2),
('公明、国民、維新、オリ', 2),
('立憲、国民、共産、社民、オリ、労働', 1),
('国民、維新、労働', 1),
('自民、公明、維新', 1),
('◯◯、❌❌', 1),
('国民、労働', 1),
('自民、維新、幸福', 1),
('幸福実現党', 1),
('公明、立憲、幸福', 1),
('立憲、国民、幸福', 1),
('維新、社民、オリ', 1),
('共産、社民、オリ、労働', 1),
('公明、共産、社民、オリ', 1),
('立憲、国民、社民', 1),
('立憲、国民、共産、社民、オリ', 1),
('自民、公明、立憲、国民、共産、維新、社民、れ新、幸福、安楽、N国、オリ、労働', 1),
('立憲、共産、社民、幸福', 1),
('○○', 1),
('国民、幸福', 1),
('公明、国民、社民、オリ', 1),
('公明、幸福', 1),
('自民、公明、幸福', 1),
('維新、労働', 1),
('幸福、オリ、労働', 1),
('維新、幸福、労働', 1),
('立憲、国民、オリ', 1),
('自民、公明、国民、維新、社民、幸福、オリ', 1),
('自民、幸福', 1),
('維新、オリ', 1),
('国民、オリ、労働', 1),
('立憲民主党', 1),
('維新、幸福、オリ', 1),
('オリ、労働', 1)]
となっていて、幸福、維新、国民、は単独で政策一致率が高いのかもしれません。 次にこれを、政策一致率の平均で見ていくと、
('国民', 213) 67
('社民', 201) 73.23880597014926
('維新', 200) 59.35
('幸福', 179) 60.66480446927374
('立憲', 97) 68.94845360824742
('共産', 92) 69.59782608695652
('公明', 88) 57.07954545454545
('オリ', 87) 68.95402298850574
('自民', 26) 47.07692307692308
('労働', 19) 67.42105263157895
('◯◯', 1) 65
('❌❌', 1) 65
('幸福実現党', 1) 48
('れ新', 1) 0
('安楽', 1) 0
('N国', 1) 0
('○○', 1) 52
('立憲民主党', 1) 74
となります。比較的どの政党も積極的に支持されている可能性が高いのではないかと思いました。
特に社民党は政策一致率と一致した人の人数が共に高く、これは実際の投票結果とは正反対なので面白いと思いました。一方で自民党の政策はあまり支持されていないのではないでしょうか…?また、幸福実現党は意外とネットユーザーとの親和性が高いのかもしれません。あくまで政策だけ見れば…
もちろんこの質問の結果が支持に絶対つながるとは限りませんので、何の役にも立たないかもしれませんが、こういう実験を色んなところでしていくのは面白いかなあと思いました。そもそも、あくまでマニフェスト?との一致なので、政党の実行力なども考慮していけば、いくら一致しているからと言って支持につながらないと思います。
最終的に分析に使ったコードは以下になりました。
import os, sys, json, re, time from collections import Counter from pprint import pprint from statistics import mean def main(): ans = [] seito2 = [] seito = [] t, _ = auth() with open('result.json', 'r') as f: js = json.load(f) for x in js: if not "retweeted_status" in x.keys(): xx = re.findall( r'考えが近い政党は(.*)でした。えらぼーと2019参院選を試してみよう! #えらぼーと #ボートマッチ #選挙 #参院選', x['text'] ) if xx != []: if xx[0] != 'ありません': xxx = list(re.findall(r'(.*)((.*)%)', xx[0])[0]) seito2.append(xxx[0]) xxx[0] = xxx[0].split('、') xxx[1] = int(xxx[1]) else: xxx = [['ありません'], None] ans.append(xxx) seito += xxx[0] pprint(sorted(dict(Counter(seito)).items(), key=lambda x:x[1], reverse=True)) pprint(sorted(dict(Counter(seito2)).items(), key=lambda x:x[1], reverse=True)) for item in sorted(dict(Counter(seito)).items(), key=lambda x:x[1], reverse=True): l = [x[1] for x in ans if item[0] in x[0]] if None not in l: print(item, mean(l)) if __name__ == '__main__': main()
おわり。
追記:集計に使ったツイートは、Mon Jul 08 16:00:10 +0000 2019 から Thu Jul 04 04:08:33 +0000 2019 の間に投稿されたものです。これはUTCですので日本では7月4日の13時ころから、7月9日の1時ころです。
H20年東京都市圏パーソントリップ調査データの分析:地域による交通機関選択の違いについて その1
パーソントリップ調査とは、国や地方自治体が、交通機関利用の実態を調べるために質問紙を配布して行う調査であり、交通実態調査とも呼称される。アンケートなので、デタラメや間違いを書くこともできるうえに、無回答者も当然多いわけで、調査結果が正しいものであるという保証はおそらくないだろうが、近年注目を集めているビッグデータの1つとして活用できる程度には、大規模で調査しがいのあるデータである。
ここではデータの正確性についてはとりあえず論じないものとする。データは ここ や ここ からダウンロード可能だ。下の方にこっそり載っている。データは3つあり、そのうち、発生・集中量と、OD量を見ていく。前者の国土数値情報データのほうが、shapeファイルとして地物データが予めついている簡単なデータである(ただしOD量はとてつもなく重い)ため、即座に視覚化しやすく楽しい。 ちなみに今ある最新のデータはH20年のものであり、少し古い感が否めない。
とりあえず、通勤に電車を使用する人の人数を視覚化(見える化w)していこう。ソフトはQGISを利用する。QGISの使い方はある程度知っている前提で書くため、知らない人には手段を再現できなくておもしろくないかもしれない点はご容赦いただきたい。
 単位は人数である。したがって当然、もともと人口の少ない地域であれば少なく出るのは当然である。だがそれを考慮しているうちにデータ分析の楽しさを見失ってしまってはつまらないので、とりあえず描画してみた。大体想像通りの結果が出ていると思う。この図を描画するには、レイヤのプロパティを開き、スタイル→段階に分けられたと進み、カラム、の右にあるεボタンを押し、式ダイアログに、
単位は人数である。したがって当然、もともと人口の少ない地域であれば少なく出るのは当然である。だがそれを考慮しているうちにデータ分析の楽しさを見失ってしまってはつまらないので、とりあえず描画してみた。大体想像通りの結果が出ていると思う。この図を描画するには、レイヤのプロパティを開き、スタイル→段階に分けられたと進み、カラム、の右にあるεボタンを押し、式ダイアログに、
case when to_int("S05a_003") = 1 then to_int("S05a_005") else NULL end
と入力する。次に分類モード「等量」、分類数「11」を選択し、分類ボタンを押す。最後に適用ボタンを押すことで描画される。以降、地図描画はこのプロセスにて行っていく。
おそらく、この図で注目すべきは、久里浜駅周辺や佐倉駅周辺、久喜駅周辺の地域において人数が多いことだろう。ちなみにこの地域の区切りは市区町村とそのまま一致するわけではない。おそらくいくつかの市区町村を一緒にしたり、逆にもうすこし細かく切ったりしている。それがどのようにして決められたのかは調べていないのでわからない。人口が均等になるように配慮されたのだろうか。しかしこれだけではまだわからない。であるから、佐倉駅周辺地域と久喜駅周辺地域が面積が広いせいで大きく値が出ている可能性も捨てきれない。しかし久里浜駅周辺地域は、周囲の同じくらいの面積の地域に比べて明らかに高い値が出ている。こういった「異常値」から、データの真の特徴を探っていくのも悪くないだろう。
一旦プロパティを閉じ、 上部バーからiアイコンをクリックすると、地物選択モードになり、地物の情報を閲覧できる。以下がそれである。説明が遅れたが、このS05a_0xxというカラム名は、 ここ ※注意:xlsファイルがいきなりダウンロードされます。 を見れば意味がわかる

この地域はもしかすると偶然回答者が多かったのかもしれない。全体的に値が大きめな気がする。その仮定で考えた場合、何か他の値との比率で考えれば値の偏りが解消される気がする(あるマンションでたまたま全住民が回答し、たまたまそのマンションが駅から近かったりするかもしれないが)。そこで、「鉄道通勤者/自家用車通勤者」を計算し、描画することにする。

先ほどとは様子がかなり大きく変わってしまった。久里浜や久喜の特異点は消えてしまい、いわゆる通勤5方面路線周辺への集中が激しくなった。しかしよく見てみると、そもそも鉄道路線周辺では地域の区切りが細かくなっているような気がする。千葉ニュータウンや小田急線沿線では1ポリゴンの面積が大きく、それが通勤5方面ばかり目立っている理由かもしれない。
そこで、面積の値別にこのデータを見ていくことにする。レイヤを右クリックし属性テーブルからフィールド計算機を開くことで、各地物の面積を地物情報として追加することができる。値の名前はareaとし、レイヤ右クリックから保存でCSVファイルとして属性テーブルを書き出す。今回は、temp.csvという名前で保存した。
ここで、jupyter-notebookとpython、pandas、matplotlibなどを使っていく。早速pandasでcsvを読み込み、地物の面積の内訳をグラフ化してみる。
%matplotlib inline import matplotlib.pyplot as plt import pandas as pd from math import log10, sqrt df = pd.read_csv('temp.csv') x = [x/10**6 for x in df[df['S05a_003']==1]['area']] plt.hist(x, bins=70)

こうなる。値が大きすぎるので、10**6で面積を割っている。ちなみにQGISで地域の面積別に色分けすると

こうなり、さっきの鉄道通勤者/自家用車通勤者分布とちょっと似ている部分があることがわかる。23区外縁部や川崎市、さいたま市などである。この情報は以降の分析に必要なわけではないが、何を見ているのか把握しておくために一応調べた。
ここで本題の、面積別、鉄道通勤者/自家用車通勤者のヒストグラムを描画する。
%matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np import math from math import log, log10, sqrt df = pd.read_csv('temp.csv') a = [0, 7500**2/4, 7500**2/4*2, 7500**2/4*3, 7500**2] for i1, i2 in zip(a[:-1], a[1:]): fig = plt.figure() d = [] s = df[df['S05a_003']==1].query(f'{i1} < area < {i2}') for x, xx in zip(s['S05a_005'], s['S05a_017']): if xx != 0 and x/xx != 0: d.append(log(x/xx)) ax = fig.add_subplot(1,1,1) ax.set_ylim(0, 20) ax.set_xlim(-5, 5) ax.hist(d, bins=50) plt.savefig(f'{i1}_area_{i2}.png')




右に行けば行くほど鉄道依存、左に行けば車依存となる。この4カテゴリは、ちゃんと色分けをすると以下の地域に該当する。

鉄道利用率の平均は、82, 59, 36, 28(%)となっている。面積が広くなればそれだけ鉄道駅から遠ざかり、車利用者も多くなると考えれば、地図に惑わされて、ああやっぱり首都圏外縁部ではモータリゼーションが進んでいるんだ、と安易に結論を出さずに済むかもしれない。一方、面積の狭いポリゴンがそもそも鉄道利用者の多い箇所に分布しているので、相乗効果で鉄道利用率が高く出ているのかもしれない。
なんかいまいちよくわからない方向に分析が進んでいる気がする。まあとにかく、地理の分析では地域をどう区切っているかということをいちいち気にしながら進めたほうが良いのかもしれない。行政区分(市区町村・町丁目)はよくできているので、うまく文化的に共通したまとまりを抽出できている可能性はあるが、伝統的な区分がコンピュータサイエンス時代でそのまま使えるかはなんともいえないとおもう。
まだまだ分析の道のりが長そうです。どうすればいいんだろう。でもこういう地道な積み重ねがないと誤った結論を出してしまう気がする。本当は統計学ちゃんと勉強したほうが良いんだけどなあ…
追記:変な間違いがあったので修正しました。
都営地下鉄・JR東日本・メトロの列車現在位置を見れるサイトを作った
東京交通オープンデータチャレンジというのがあります。鉄道駅に時々広告が貼ってあるのでご存知のかたもいるかと思います。今年で三回目だそうです。アカウント取得は誰でもでき(たぶん)、アカウントがあるとAPIを使うことができます。 正直、使い方が公式サイトを見てもよくわからないんですが、まあ、適当にいじってるとそのうちわかります(たぶん)。
それで、都営地下鉄とJR東日本の首都圏の列車(両毛線・相模線のような路線は無理だったはず)、メトロのすべての位置情報が取得できるようになってます。都営地下鉄は最近追加されたようです。メトロの位置情報を見れるサイトは第二回までのオープンデータチャレンジで色々作られているようですが、都営地下鉄に関してはまだ少ないため、公開しようと思いサイトにしました。それがこちらです↓

オープンデータとして、メトロの路線記号?の画像が配布されていたので、メトロに関してはそこから呼び出せるようにもしました。とくにJRは路線が多すぎて探すのが面倒なのと、ページに説明が少なすぎてなんのサイトなのかよくわからないので、今後の改善点にしていきます。
構成
ドメインはvalue-domainで900円ほどで購入(なんだこのドメインは…)、サーバーは以前から契約している月1000円で1GBほどのconohaのVPS、サイトはpythonのdjangoというフレームワークで作っています。最近はdjangoで試しにアプリを作るのが流行ってる気がする
APIを叩くプログラムを作って、djangoのフォルダ内に設置し、一分間隔で実行することによってデータを更新しています。
表示画面
 列車番号、行き先、遅延時間(秒)の順番で表示しています。各鉄道会社のスマホアプリみたいな凝ったデザインはできていません。必要な情報が簡単に見れることをコンセプトにしたいため、あまり凝ったデザイン好きではないのですが、ちょっと味気ないかなという感じがしてます。各列車情報はクリックするとその列車の時刻表にジャンプすることができます(ここも自作)
列車番号、行き先、遅延時間(秒)の順番で表示しています。各鉄道会社のスマホアプリみたいな凝ったデザインはできていません。必要な情報が簡単に見れることをコンセプトにしたいため、あまり凝ったデザイン好きではないのですが、ちょっと味気ないかなという感じがしてます。各列車情報はクリックするとその列車の時刻表にジャンプすることができます(ここも自作)
 列車番号というのがどういう規則でつけられているのかわからないのであれなんですが、土休日と平日で同じ列車番号の列車が存在することがあります。その場合はちょっと見にくいかと思います。
列車番号というのがどういう規則でつけられているのかわからないのであれなんですが、土休日と平日で同じ列車番号の列車が存在することがあります。その場合はちょっと見にくいかと思います。
今後
ホーム画面に簡易的に全体の遅延状況を表示したり、統計情報を表示したり、ビジュアル面を改善したり、ユーザー(たぶん今はほとんどいない)の意見を取り入れたり、いろいろ改善していこうと思います。
ubuntuでCPU温度のログを取る
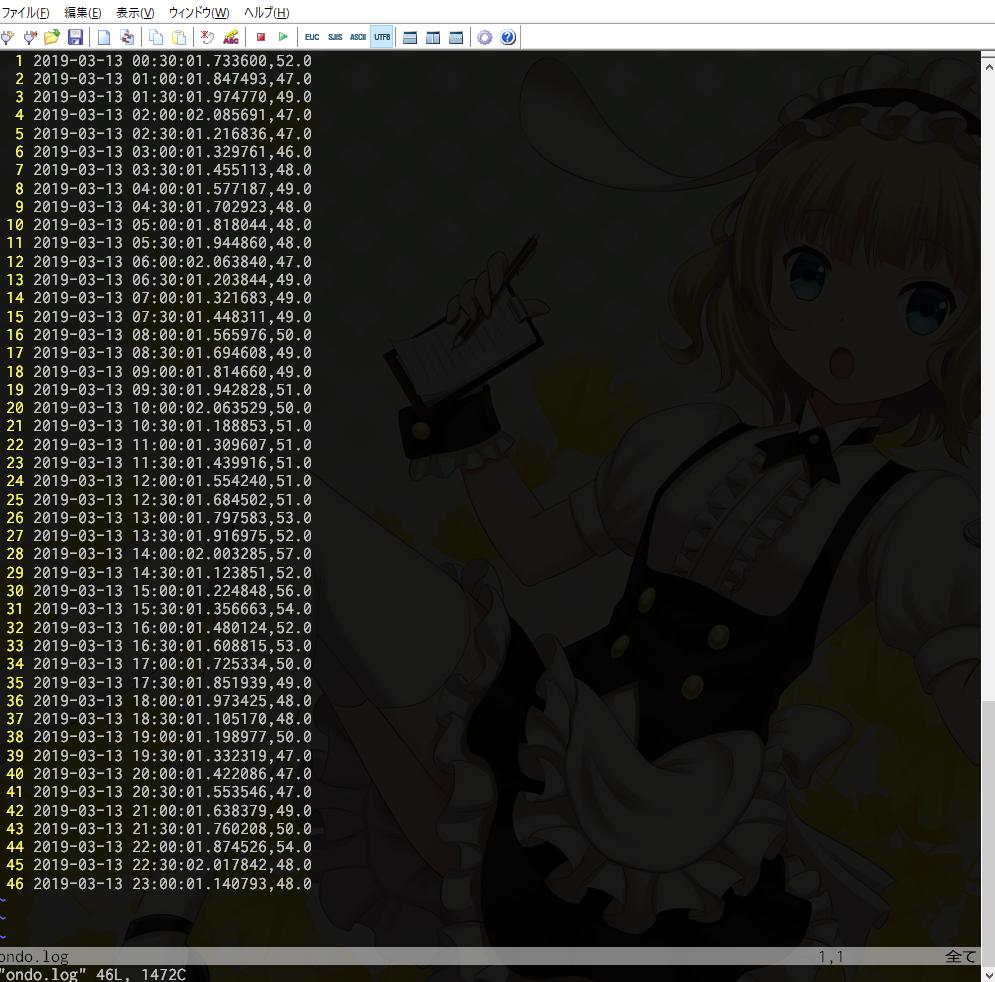
sensorsっていうパッケージを使うとCPU温度の取得ができるみたいです。sudo apt-get install lm-sensorsとか、sudo apt install lm-sensorsとかで入れることができるはずです。sudo sensors-detectで検出するCPUかなんかの設定ができるみたいですが、適当にやっただけでもCPUが検出できました。
ただ自分の環境だと何故かCPU0とCPU2しか検出できませんでした。まあCPU0の温度が取得できれば自分の場合困らないので、それを取得するプログラムをpython3で記述しました。
[python] import subprocess as p import os from datetime import datetime as dt temp = p.run(['sensors'], stdout=p.PIPE).stdout.decode('utf-8') temp = temp.split(os.linesep)[6].split(' ') for x in temp[2:]: if x != '': temp = x[1:-2] break temp = float(temp) print(f'{dt.now()},{temp}') [/python]
自分の場合、$ sensorsで標準出力に表示される六行目に、Core 0: +47.0°C (high = +95.0°C, crit = +105.0°C)のようにCPU0の温度が表示されていたので、それを取得して、整形して標準出力しています。正規表現とかつかって抜き出してもいいと思います。これをCSVに書き込むようにしてもいいと思います。subprocess.run(['command'], stdout=p.PIPE).stdout.decode('utf-8')で、コマンドの標準出力を受け取ることができるというのがポイントです。
これを、crontab -eで自動実行させます。自分は三十分に一回実行させています。
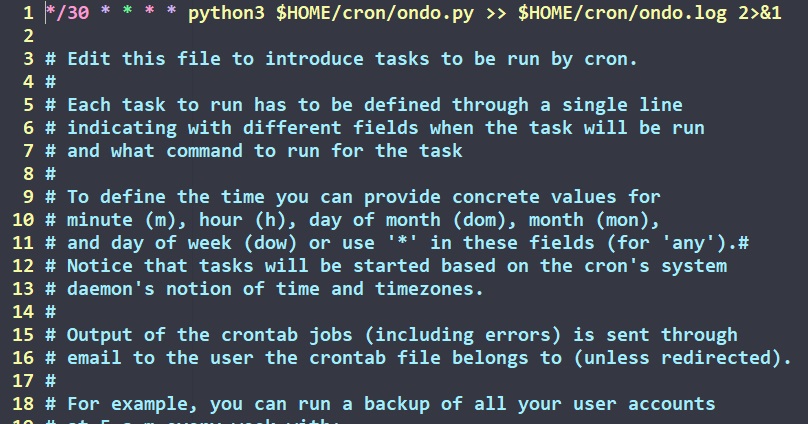
自分はこのように設定しました。$HOMEは何も書かなくてもホームディレクトリのパスに変換されます。